Canonical Tag
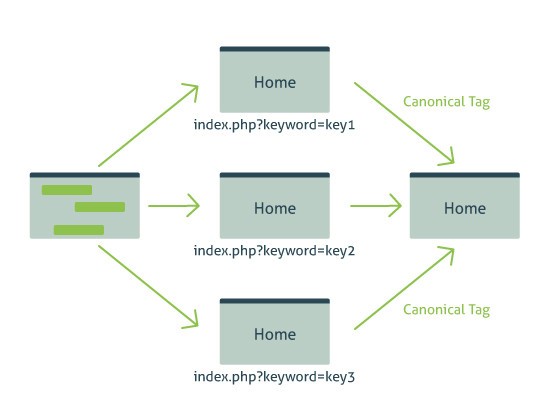
Im Jahr 2009 wurde der Canonical Tag eingeführt – warum? Eines der größten Schwierigkeiten von Suchmaschinen ist der Kampf gegen Duplicate Content. Identische oder ähnliche Inhalte auf Websites führen nicht nur dazu, dass Suchmaschinen wie Google unnötig viele Seiten crawlen, sondern gleichzeitig, dass die indexierten Pages dem User keinen Mehrwert bieten. Folglich werden die Suchergebnisse schlechter, was im Gegensatz zu den Zielen der Suchmaschinen steht: Nutzern die bestmöglichen Ergebnisse zu Suchanfragen zu liefern. Dafür legt besonders Google im Rahmen moderner Suchmaschinenoptimierung viel Wert auf Unique Content. Der Canonical Tag sorgt für Abhilfe, da er als HTML-Angabe im Quellcode einer Webseite auf Originalinhalte beziehungsweise Duplicate Content hinweist. In der Folge weiß der Suchmaschinen-Crawler, dass die kanonische (bevorzugte) URL als Originalquelle zu betrachten und für den Inhalt zu indexieren ist. Eine Garantie, dass die bevorzugte URL indexiert wird, gibt es jedoch nicht, wenngleich Suchmaschinen diesem Hinweis, dass eine URL kanonisch ist, in der Regel folgen.
Anwendungsbereiche von Canonical Tags
Der Canonical Tag wird gegen Duplicate Content eingesetzt, was die Kenntnis von identischen oder ähnlichen Inhalten voraussetzt. Hieraus ergeben sich unterschiedliche Möglichkeiten beziehungsweise Situationen, in denen der Canonical Tag gesetzt werden sollte. Viele Webseiten sind über unterschiedliche URLs aufrufbar (z.B. mit und ohne www.), was folglich zu Duplicate Content führt. Ebenso können URLs mit und ohne Groß- und Kleinschreibung oder Session-IDs das Problem von doppelten Inhalten hervorbringen. Zu beachten sind weiterhin die verschiedenen Versionen von Seiten, beispielsweise als Druckausgabe oder PDF. Problematisch sind auch Pressemitteilungen, die auf zahlreichen PR-Portalen im Internet veröffentlicht werden, gleichzeitig aber auch als Inhalt auf der eigenen Webseite.
Die Ausweisung einer kanonischen URL erfolgt in der Regel im Head-Bereich des Quellcodes einer Webseite, damit Suchmaschinen-Crawler den Verweis als Original direkt zu Beginn des Crawling-Prozesses erkennen. Der Canonical Tag besteht aus einem Link-Attribut und dem Verweis rel=“canonical“ und sieht im Quellcode wie folgt aus: <link rel=“canonical“ href=“http://www.beispiel.de/Beispielseite“/>. In diesem Beispiel wird die gesamte URL angegeben (mit www.), was von Suchmaschinen favorisiert wird und der Idealfall sein sollte. Andernfalls kann es wieder zu Missverständnissen beziehungsweise Fehlern bei der Indexierung von Seiten kommen.
Wann ein Canonical Tag nicht hilfreich ist
Canonical Tags sind wichtig, um darauf hinzuweisen, dass eine URL kanonisch ist, doch nicht in jedem Fall ist es sinnvoll ein Canonical Tag zu setzen bzw. löst der Verweis nicht in jeder Situation das Problem. Das trifft vor allem auf den Content-Klau zu. Hierbei wird die gesamte Webseite kopiert und Inhalte werden unter einer anderen URL dargestellt. In diesem Fall entsteht Duplicate Content, der von Webmastern nicht einfach zu entfernen ist, da das Canonical Tag nicht auf der fremden Seite eingebaut werden kann.
Alternative zu Canonical Tags: Links mit Redirect
Ein alternatives Instrument zu Canonical Tags sind Links, über die ein Redirect erfolgt. Gerade, wenn es für ein Keyword mehrere Synonyme gibt, die allesamt ordentliche Suchanfragen generieren, bietet sich solch eine Weiterleitung auf eine entsprechend optimierte Seite an. Das ist eine bessere Lösung als mehrere Kategorien zu erstellen, die aber die gleichen Produkte anbieten. In solchen Fällen braucht es auch nicht unbedingt einen Canonical Tag.